
We recently spoke to Raj Koneru and Prasanna Arikala of Kore AI on the VUX World podcast, discussing Large Language Models (LLMs) and the forecasted impact they’ll have on the creation of enterprise AI assistants.
Raj shared his thoughts on the types of NLU systems that exist today, and the benefits of each. This will help creators understand a little more about the way LLMs work and how you can tune them vs the industry standard intent-based NLU models.
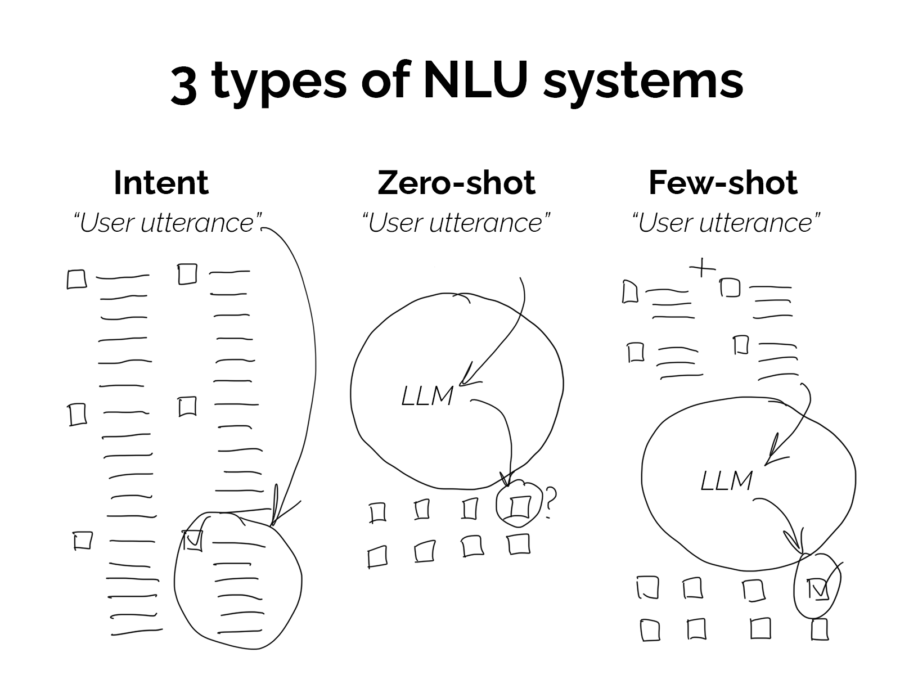
Three types of NLU
1. Curated, intent-based model
This approach involved using an intent-based NLU with customised intents and training data, which is the most common approach used by most businesses today. Here, you gather your own training data to form your own intents based on your business needs.
User utterances are then matched and classified against your intents based on the model’s ability to find a pattern between the utterance and sample training data it has in its model.
This works well for simple utterances, but struggles to understand things like long form sentences and utterances that are distinctly different from your sample training data.
Most NLU systems have used this approach so far, but the emergence of Large Language Models over the last 3 or so years is changing this.
2. Zero-shot model
This approach involves using a transformer-based Large Language Model (LLM) to generate understanding of a customer utterance without the need to provide training data.
Large Language Models are trained on billions of data points and huge corpuses of data from readily available text online. They use sources such as Reddit, Wikipedia and others to train models on how to identify and reproduce patterns in language.
These advanced pattern matching systems perform great feats and can be used out-of-the-box to do things like intent classification and entity extraction.
Most of the LLMs available today, because they’re trained on general text data from the web, they’re not honed for specific business purposes. This means that out-of-the-box performance might only get you so far.
Also, because of the inherent limitations of pattern recognition, they’re prone to making a few mistakes here and there. This can result in some utterances being misclassified. However, I haven’t seen an assistant built on an intent-based system to date that doesn’t trip up and misclassify (or not match) on some utterances, either.
3. Few-shot model (hybrid):
This approach takes the best of both worlds and uses word embeddings to tune LLMs according to a few example phrases of the types of utterances you’d expect for a given intent.
This is how you can tune a Large Language Model to a specific use case or set of intents. By feeding it a few examples of different training phrases, you can provide it with additional context and influence how it classifies something.
This not only means that you can tune it for your specific business use cases, but providing some sample data means you can reduce the likelihood of it misclassifying.
According to Raj, you could even use an LLM to generate sample training data, which you’d then use to train your few-shot model. This can give you the efficiency of a zero-shot model, whilst ensuring that the model is tuned to your business needs. This gives you even more control, as you’re able to both influence the training and tuning of the model, as well as validate the output from it.
Multi NLU approach
“LLMs are highly accurate at classifying an intent, except when they get it wrong.”
Raj Koneru, CEO, Kore AI
As mentioned, an LLM misclassifying an intent can happen because LLMs are trained on world data from across the internet. They’re not highly tuned for your business use cases.
For an end user to ask ChatGPT a question, for example, and ChatGPT gets it wrong, it’s not consequential. For a user to ask a question of a business and the business gets it wrong, that is more consequential, especially for high-emotion or important use cases.
Therefore, the best approach is to utilise all three models above where relevant. And we’ll be diving into how you can architect this arrangement with Kore AI in an up-and-coming post.
Stay tuned.
For more information on Kore.ai, you can book a demo with the team or book a free consultation.


