
At Google I/O, LaMDA 2 was announced. Google’s second iteration of its large language model, LaMDA.
It stands for Language Models for Dialogue Applications and is intended to make having autonomous conversations with machines possible.
It, apparently, can answer questions and, using the context of the question or answer, generate prompts to continue conversations. It can allegedly take pretty complex queries on complex topics and summarise answers plainly, as well as hold multi turn conversations around a specific topic, like ‘dogs’, the ‘ocean’, and others.
Marketing vs reality
As impressed as I tend to be when I see new releases of language models like this, Open AI’s GPT series or this recent one from AI21, I still can’t help but wonder.
Since reading this piece by Emily M Bender on crushing AI hype, I can’t help but scrutinise these kind of announcements. I’m wondering:
a) the incentives of the companies creating the models (and those reporting on them)
b) the reality of the technology vs how it’s explained
c) the practical real world application potential of the technology
d) how you or your business will benefit from it or be impacted by it
Long term incentives
Google is obviously incentivised to create large general language models like this. Long term, If it can generate language and conversations with high levels of accuracy, then what does that mean for Google search? What does it mean for Google Assistant?
Some of the examples demonstrated at Google I/O have the potential to disrupt the very concept of a website.
The List It feature takes a task prompt, like “I want to grow a veg garden”, and generates a list of things you’ll need to do in order to grow one. It’s complete with detailed guidance and tips, just like you might find on Gardeners World or similar sites.
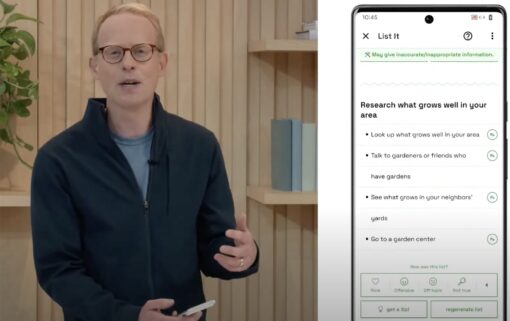
The long term impact for brands
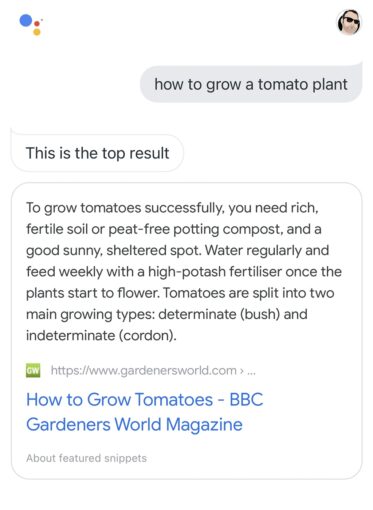 When Google Assistant answers questions by taking content from the internet, it attributes that answer to the website it pulled it from.
When Google Assistant answers questions by taking content from the internet, it attributes that answer to the website it pulled it from.
With something like LaMDA 2, the language model is so big that it won’t even know where it got the content from. In this instance, it’ll be a concoction of thousands of gardening websites.
Google is essentially building its own, first party knowledge base, using content from across the internet. This could mean that Google would have more control over Google search and Google Assistant. This in theory means better customer experience and increased usage of Google services.
However, you can potentially begin to wave goodbye to attribution on Google Assistant or, potentially in time, positions on search engine results pages, as more traffic is served by Google directly.
Short term
The short term concern is a lot simpler. Google has to compete to be known as the leading AI company on the planet. It has to build large language models and push forward the AI cause and to remain to be seen as the leading AI company on the planet.
Regardless of whether any of this makes it to production, Google still has to show its impressive progress because, if it doesn’t, Open AI or others will.
LaMDA 2 is a show of muscle and technical prowess, rather than V1 of the future. It’s Google showing you its progress to position itself as a leading AI company.
The reality of the technology
LaMDA 2 certainly looks like it has potential, as do all these large language models when they’re unveiled.
Being able to take a prompt like “tell me about the deep ocean” and receive a sensible response, with follow-up prompts to continue the conversation is impressive. Certainly considering that the prompts are produced by the system on its own, after having digested and summarised related content, and prioritised which prompts would be most useful, given the context of the conversation… All things that are usually manual jobs for conversation designers and architects today.
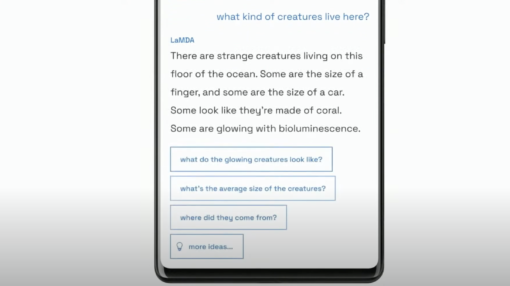
However, most of these large language models, LaMDA 2 included, are miles away from full scale production. In fact, it may never reach production.
LaMDA, like GPT-3 and others, still has issues, producing irrelevant or inaccurate or offensive or out-of-context information.
And, to be fair to Google, it does openly acknowledge that there is still work to be done to improve its accuracy and it is not perfect. Examples of LaMDA2 shown at I/O, and the test case examples available in the up-and-coming test suite, AI Test Kitchen, are just that: tests.
“We’re at the beginning of our journey to make models like these useful to people” explained Sundar Pichai, CEO, Google.
Google describes these test cases as “examples of what it would be like” to use LaMDA2.
Practical application
The real concern for Google is taking this test bed technology and making it ready for full scale, autonomous production usage. A deployment that doesn’t give wrong answers, incorrect facts or offensive or malicious content.
And long term, it’s very difficult to squash issues in self-learning systems or language modals as large as this.
If it’s making up answers on the spot using a next-word-prediction algorithm, based on the configuration of 178 billion parameters, after having digested all the words across the entire internet, books and more, then how on earth will you even be able to monitor what it gets wrong in the first place, in practice and at scale? Which one, few, bunch, stadia or galaxies of parameters are the ones that need work?
It’s very hard.
I’m not saying it’s not impressive. It certainly looks impressive in promo videos and in controlled demo environments with reliable test use cases. Taking that and rolling it into Google search or Google Assistant, though, is a whole other ball game entirely.
How it affects you and your business
The challenge for most businesses reading this is that these large language models aren’t for you. They’re not going to help your customers with your use cases and your knowledge. Maybe never.
These are incredibly large generalistic language models that have been trained on general knowledge, opinions and facts. None of this knowledge (or very little of it) will be relevant for the kind of questions the customers have for your business. It’s a Google thing, for Google customers, and that’s pretty much it, for now.
Whether LaMDA 2, 3, 4, or 28, will be the LaMDA we see in Google’s production products, who knows. I suspect we’ll get there eventually, but slowly.


