LLMs have made quite a mark haven’t they? They were just a whisper within conversational AI in the past few years. Now they’re getting an unbelievable amount of exposure. It’s been the year of ChatGPT.
Due to the fact that LLMs can convincingly talk about pretty much anything, most of the time, people have started to wonder if we need NLUs anymore. Why bother to spend time and money refining your intents, training data and entities, when an LLM can happily chat away for hours without it? And weren’t NLU-based bots too restrictive anyway? They could only take users down the paths you had predefined, so they couldn’t help anyone who came with a need you’d never considered.
In reality, though, it’s not either/or. And you should consider what happens when you take the best of both worlds. Each has their strengths and weaknesses – when used together, you can solve many of the issues the conversational AI industry has struggled with for years.
That was the focus of a recent ServisBOT webinar with Cathal McGloin, CEO, ServisBOT, and Kane Simms.
Here’s three smart ways to use LLMs alongside your NLU.
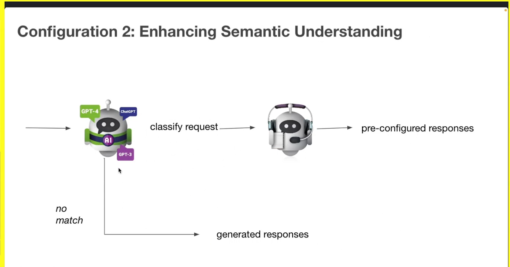
Using an LLM-fronted bot for improved semantic understanding
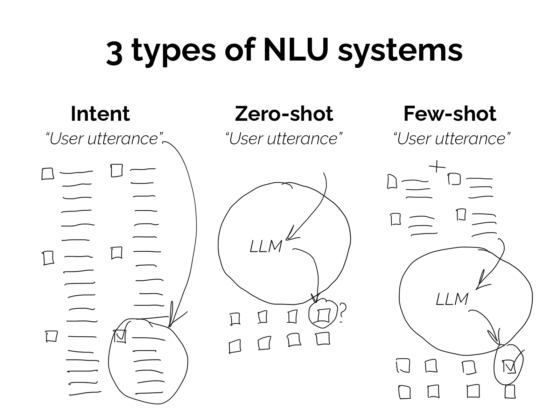
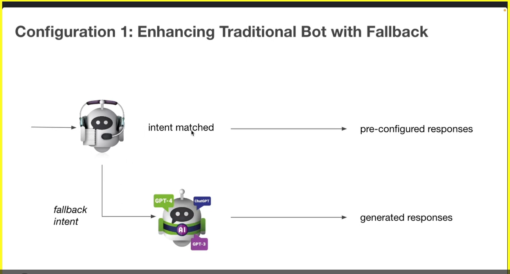
NLUs need to be trained so that the various things a user can say to it will be classified to specific intents. While training gives you control over the result – for example you can train the NLU so that a user who says ‘what’s my balance’ will be matched to the balance_check intent – it also means that you have to define, in advance, the various things users might say and need to find examples of those utterances. You define the rules that will be used to filter language.
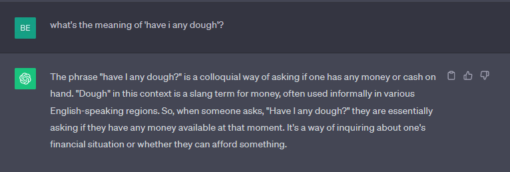
LLMs are different. The likes of ChatGPT have been trained on a vast dataset which means that it should be able to predict how language behaves. That means that users can ask ‘what’s my balance’ as well as ‘how much money have i got’ or even colloquial phrases such as ‘have I any dough’ and the LLM should be able to match those words to the most likely intent (without giving tips on bread-making).
This means there’s great potential for using LLMs to front-end conversational AI assistants, where they can parse the user’s input to glean their need from it, and then route it to the correct intent.
Due to the fact that LLMs have been trained on vast datasets, they should be better suited at picking up the various ways users can say things.
Cathal presented a demo for an embassy where a user was asking about visa applications. Semantically similar phrases such as ‘how much does it cost for a visa’ and ‘how much does it cost to apply for a visa’ were correctly identified by the LLM as the user’s need to find out the price. The NLU treated each differently however, and while it provided pricing as a response to the first utterance, it treated the second utterance as a request to find out about the application process. That’s because the word ‘apply’ had higher weighting over ‘cost’ in the NLU model, which led to the NLU misinterpreting the question.
While an NLU could be updated to include this new utterance, and correctly match it to the right intent, as Cathal says, the benefits of using an LLM instead are: “twofold – one is it understands meaning and I don’t have to tell the bot the difference between applying for a visa and the cost of the visa anymore… and the second big one is, I actually don’t have to give my bot any training data. I just have to give it very clear language to say ‘this is the intent called ‘cost of a visa’ and I use the LLM to [know] when to trigger it.”
You still want to create intents, to ensure that users are directed down suitable paths, but your need for training data could be reduced if you use an LLM in this way, according to Cathal.
Creating guardrails around an LLM with a pre-designed flow
Here’s an innovative hybrid.
Flowcharts are common artefacts used when designing conversational AI assistants. They essentially allow you to pre-design the start, middle and end of a conversation. You start by outlining the boundaries of the experience (who the bot is, and what it can and can’t do), then the middle is where important information is shared or collected by the bot, and the various endings are the resolutions of different user needs.
In the past, the flowchart would define the paths a conversation could go down, and then the NLU would be used to ensure that it actually works in a live conversation. The NLU would capture the things users say and route them to the path that seems most correct, based on how the NLU was trained.
Cathal presented an alternative design. A flowchart was used to define the experience, but there was no NLU. Instead, the user’s inputs were being sent to ChatGPT which generated the response.
Guardrails within the design, meaning that the LLM isn’t free to respond in any way it sees fit. For example, jailbreaking LLMs is an unfortunate issue that needs to be considered when utilising them. Jailbreaking is basically hacking. Bad actors try to find a way to get the LLM to share something that they’re not supposed to, such as getting a bank’s bot to reveal how to break into the bank.
Cathal had predefined the experience within his flow, by telling ChatGPT to play the role of a security analyst, and telling it that it shouldn’t respond to users who are trying to elicit information that the bot shouldn’t provide.
This highlights how LLMs require us to change our thinking when creating conversational AI. Rather than designing everything we want to include in the bot, instead we give the bot a vast information resource and tell it everything we want it to exclude from its responses.
There are benefits to working this way which in the past would have required an enormous amount of work. For example, it’s possible to ask the bot a question in German, have it formulate a response for you that was sourced from an English document, and then the bot replies to you in German. In the past that would have required the coordination of the design, development and localisation teams to achieve, but with an LLM it’s apparently simple and easy, according to ServisBOT.
With this approach, you forego the challenge of training an NLU, and instead need to define how the LLM is constrained. It’s questionable how much time you save, as you likely need to regularly update the guardrails around the LLM as new issues are discovered.
Using an LLM to test and train a bot
NLUs are never ‘done’. They don’t work well when they have a ‘small’ amount of data (generally speaking, less than 50 utterances per intent, but ideally you want 100s or 1000s of utterances per intent). The challenge is that the more you add into them to try and ensure that the bot will interpret a user’s utterances correctly, the more likely you are to have confusion within the model, where it has false positives and false negatives.
It’s common practice to keep refining an NLU’s training to try and improve this, but it’s time-consuming work. You need to identify the confusion, find and add data to improve it, then train it and test it, and then analyse whether you’ve made it more robust or possibly made it worse. It’s not uncommon to discover that a change you made to the data with the best intentions made the model worse.
LLMs could help here. As they’re vast stores of data that contain various ways people say different things, an LLM could be used to first test the NLU with semantically similar utterances to check how well it identifies them, and secondly add additional data if it finds a weak spot.
Automating the testing of an NLU and the generation of new training data to strengthen it could potentially make the management of the NLU much easier. On any project the NLU’s training data should grow as the bot has more interactions. That’s good practice – you improve the training data as you observe how users talk with your bot. The challenge is that over time it becomes harder to manage. Using an LLM in this way can help a great deal to stay on top of the complex relationships between your intents and training data.
Summary
There’s years of hard-earned knowledge around the design and maintenance of NLUs. They work well when you know what your user wants to do and how they’re likely to ask for it, and the process you need to go through to service their needs. There’s no reason to bin something that works just yet – a well trained NLU is robust enough to service most user’s needs.
While there are some who have been working with LLMs for years, they’re still a black box. As Cathal shows, there’s plenty of inventive ways to utilise an LLM alongside your NLU to glean the benefits of both. They can help users who have an unusual need, or express themself in an unexpected way. That stuff happens everyday with most bots, so LLMs are an asset if they help more users achieve their goals.
Why pick one or the other? When they’re combined you can help more users. Isn’t that what this is all about? Before we go all-in on one piece of technology, we should consider how the tech serves the people who use it, in all their various ways. With that in mind, you can see the benefits of both an NLU and an LLM.
Thanks to Cathal McGloin and the ServisBOT team for joining us for the webinar. If you’d like to take ServisBOT up on their offer of a Complimentary Bot Accuracy Analysis, you can sign up here.
Complete a short anonymous survey from ServisBot to share how your business uses NLU and LLM in building conversational AI experiences for a chance to win an iPad or a Google Pixel tablet!