Critical foundational knowledge on Natural Language Understanding (NLU) for anyone interested in learning about conversational AI or conversation design.
Natural Language Understanding (NLU) is being used in more and more applications, powering the world’s chatbots, voicebots and voice assistants. With 67% of companies claiming to be working on conversational assistants, and 51% of companies forecast to spend more on conversational AI than on mobile apps, it’s likely only a matter of time before you and your team encounter working with NLU systems.
Most of the guidance on Natural Language Understanding (NLU) online is created by NLU system providers. Some providers work in unique ways and so, if you’re just learning about conversational AI and conversation design, this plain English guide will get you up to speed on the basics of Natural Language Understanding; what it is, how it works and how to use it.
What is natural language understanding (NLU)?
Natural language understanding is an artificial intelligence technology who’s main job is understanding spoken or written words and phrases.
It turns language, known technically as ‘unstructured data’, into a ‘machine readable’ format, known as ‘structured data’. This enables other computer systems to process the data to fulfil user requests.
Most of the time, NLU is found in chatbots, voicebots and voice assistants, but it can theoretically be used in any application that aims to understand the meaning of typed text.
How does natural language understanding (NLU) work?
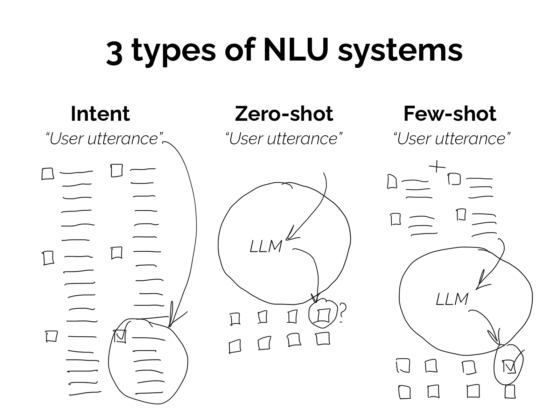
NLU systems work by analysing input text, and using that to determine the meaning behind the user’s request. It does that by matching what’s said to training data that corresponds to an ‘intent’. Identifying that intent is the first job of an NLU.
What is an NLU intent?
An intent is an action that a user intends to perform. You can think of it as the meaning behind what the user said. For example, you might give your taxi chatbot or voicebot a ‘book’ intent if you want to allow your users to book a taxi.
How does an NLU determine an intent?
NLU systems determine the intent by taking the input text written by the user (or transcribed by a speech to text system), and matching that to similar text in its ‘training data’ (more on training data in a moment).
What is NLU training data?
Training data, also called ‘sample utterances’ are simply written examples of the kind of things people are likely to say to a chatbot or voicebot.
The training data is organised into ‘buckets’, with each bucket containing different examples of phrases that have the same or similar meaning. For example: “I’d like a taxi please” and “Book me a ride” could both be examples of training data that you’d put into one ‘bucket’. That’s because both of those phrases mean the same thing: the user wants to book a ride.
Whereas; “How much would it cost?” and “Can I get a quote?” would both be examples of training data that you’d put into a different ‘bucket’. That’s because both of those phrases mean the user is wanting to know how much a ride would cost.
Each ‘bucket’ is given a specific label and that label is, you guessed it, the ‘intent’.
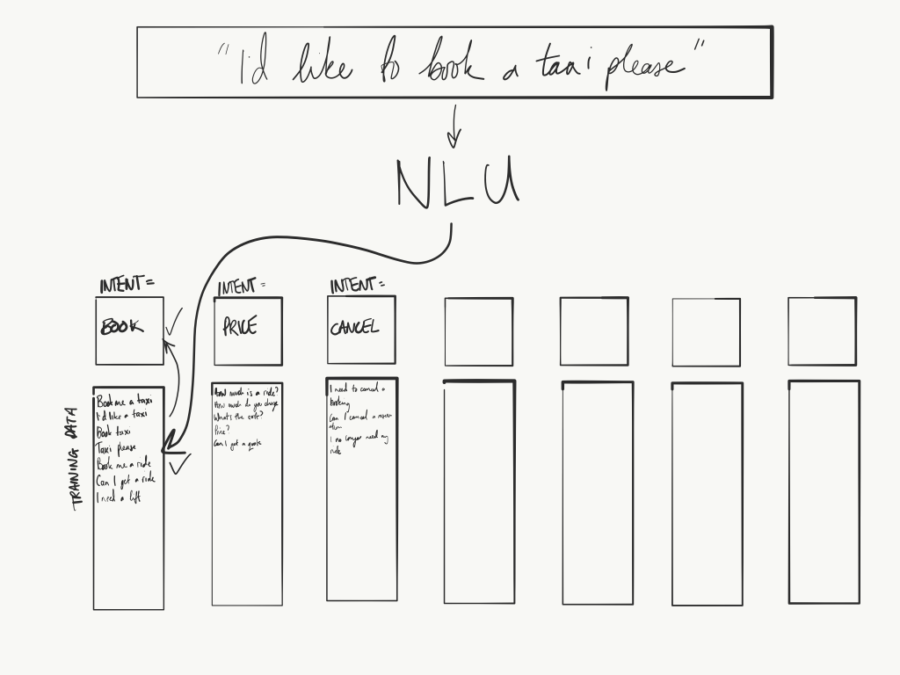
An example of how an NLU matches an utterance to an intent.
The second job of an NLU, as well as identifying intents is to also identify ‘entities’.
What is an NLU entity?
An entity is a specific piece of data or information that’s particularly important, sometimes crucial, for a given intent. For example, your ‘book’ intent might require a ‘starting location’, a ‘destination’, a ‘date’ for collection and a ‘time’. All of those are entities that are required in order for the ‘book’ intent to be successfully carried out.
Entities can have a variety of values, such as dates, times, locations, towns, cities, numbers or any words, phrases or values that you specify.
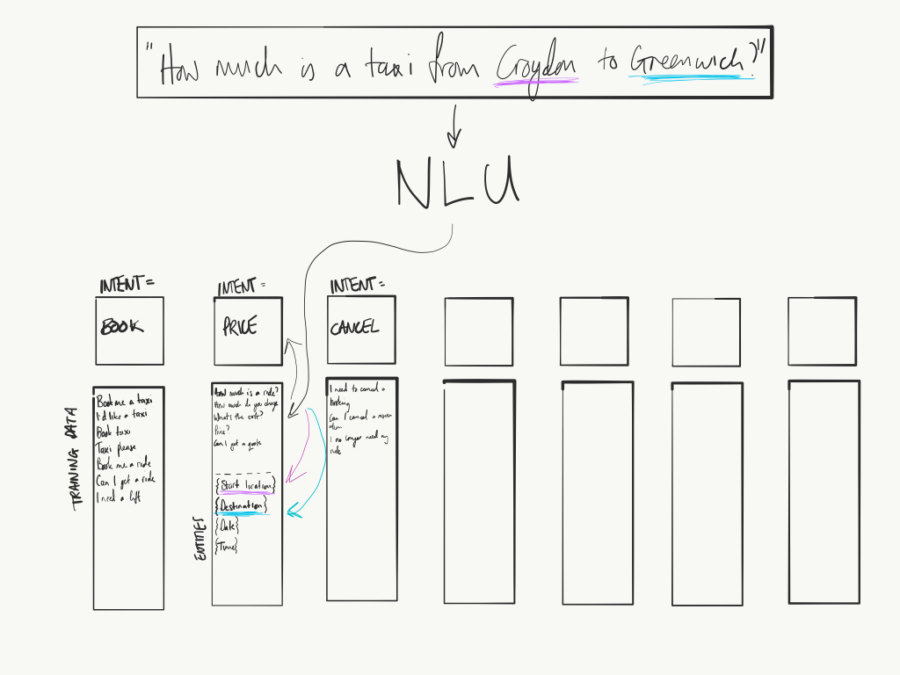
Example of Natural Language Understanding (NLU) entities and training data
Once you have your intents, entities and sample utterances, you have what’s known as a language model.
The purpose of NLU training data
The purpose of providing training data to NLU systems isn’t to give it explicit instructions about the exact phrases you want it to listen out for. It’s to give it samples of the kind of things you want it to listen out for.
Once you’ve given the NLU training data, whenever it processes a string of text from a user, it uses its knowledge, built over millions of prior interactions with all other customer’s and training data gather over its entire lifetime, to determine the likelihood of a given utterance corresponding to one of your intents.
That means that a user utterance doesn’t have to match a specific phrase in your training data. Similar enough phrases could be matched to a relevant intent, providing the ‘confidence score’ is high enough.
For example, let’s say you have a restaurant booking chatbot with the following sample utterances:
- I’d like to book a table
- Can I make a reservation
- Make a booking
- I’m looking to reserve a table
Now let’s say the user types the following into your chatbot or speaks it to your voice assistant:
“Can I reserve a table?”
The phrase “Can I reserve a table?” doesn’t exist in the list of sample utterances you trained the system on, yet it’s close enough and follows the same patterns. Therefore your NLU might recognise that phrase as a ‘booking’ phrase and initiate your booking intent.
How does an NLU know to match a similar phrase to intents?
If you use an NLU like Amazon Lex or Google DialogFlow, you’re tapping into the core technology of two of the biggest AI provider’s in the world. You’re utilising the training data and models that the 10,000+ engineers at those companies have trained those systems on over the last decade or so.
You’re also utilising the constantly evolving and improving models as those engineers learn from millions of customer interactions. Millions of people speaking to Alexa, Google Assistant and Lex/DialogFlow-powered chat and voicebots every day is all feeding into and improving the NLU’s ability to understand what people are saying.
And it’ll only get better over time, possibly requiring less training data for you to create a high performing conversational chat or voicebot. That means it’ll take you far less time and far less effort to create your language models.
What is a language model in NLU?
A language model is simply the component parts of a Natural Language Understanding system all working together. Once you’ve specified intents and entities, and you’ve populated intents with training data, you have a language model.
How to build a language model
If you want to use an NLU to build a language model, there are three steps you should take:
- Specify your intents: make a list of the things you want your bot to be able to handle.
- Specify your entities: make another list of the pieces of data that you’ll need to capture for each intent.
- Create sample utterances: make a series of lists, one per intent, with examples of phrases that customers can say to trigger a given intent. These sample utterances should also include entities. For example “Can I book a taxi for {date} at {time}“.
Note: this is the steps to follow to simply build a language model. Before doing this, you should design your conversations first.
Those are the high level component parts of an NLU. Now let’s zoom out and explore where NLU sits within the broader field of AI.
Where does NLU fit within artificial intelligence (AI) more broadly?
Natural Language Understanding is a sub-component of Natural Language Processing (NLP), which is itself a sub component of AI.
What is natural language processing (NLP)?
Natural Language Processing (NLP) is an umbrella term encapsulating all elements of natural language processing technologies, including natural language understanding (NLU), automatic speech recognition (ASR), sentiment analysis, voice biometrics and more.
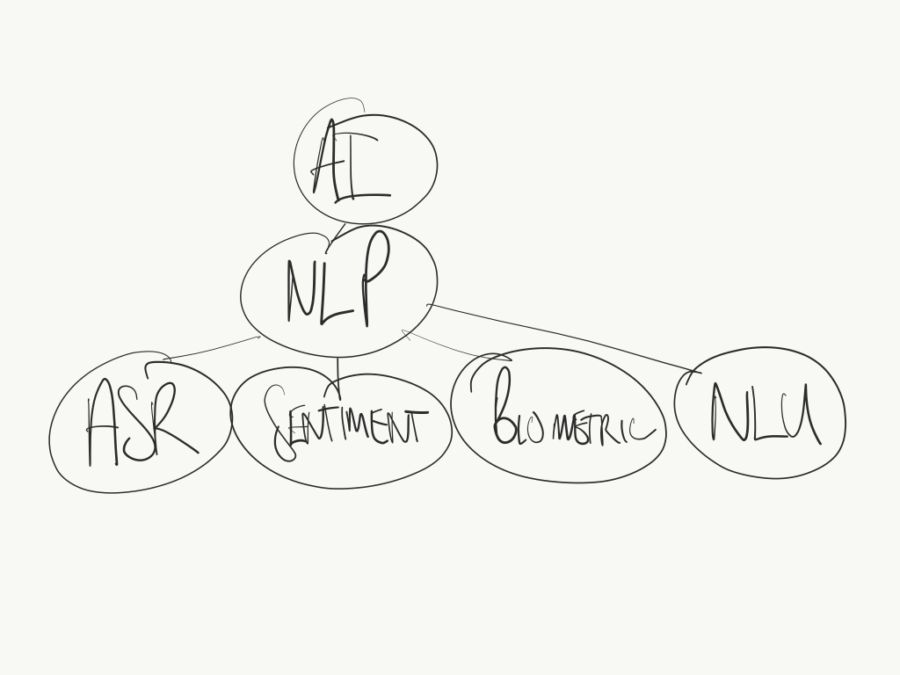
Natural Language Understanding is a sub-component under Natural Language Processing (NLP), which is a sub-technology under AI.
NLU is simply concerned with understanding the meaning of what was said and how that translates to an action that a system can perform.
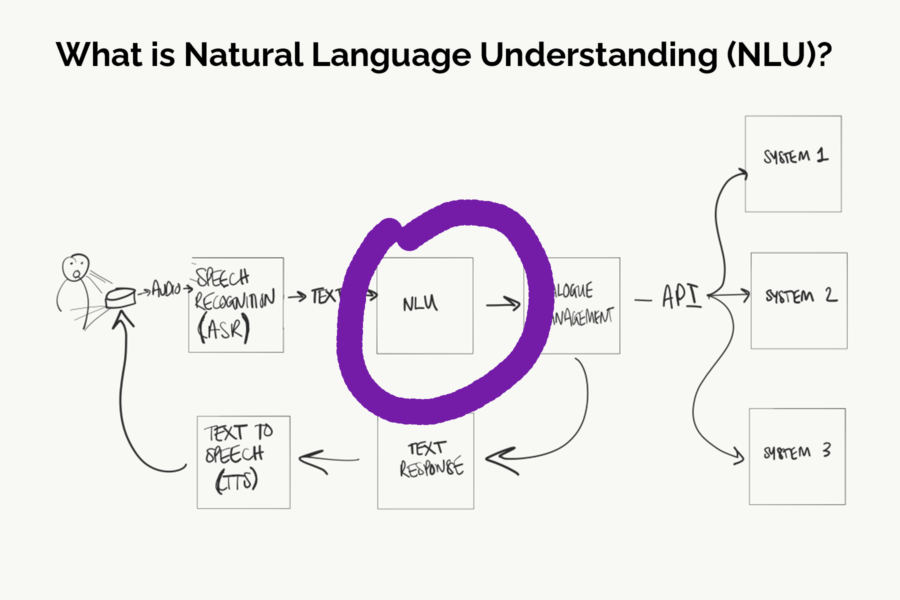
Where does Natural Language Understanding (NLU) sit within the conversational AI ‘pipeline’?
With text-based conversational AI systems, when a user types a phrase to a bot, that text is sent straight to the NLU. The NLU is the first things that happens in a chatbot.
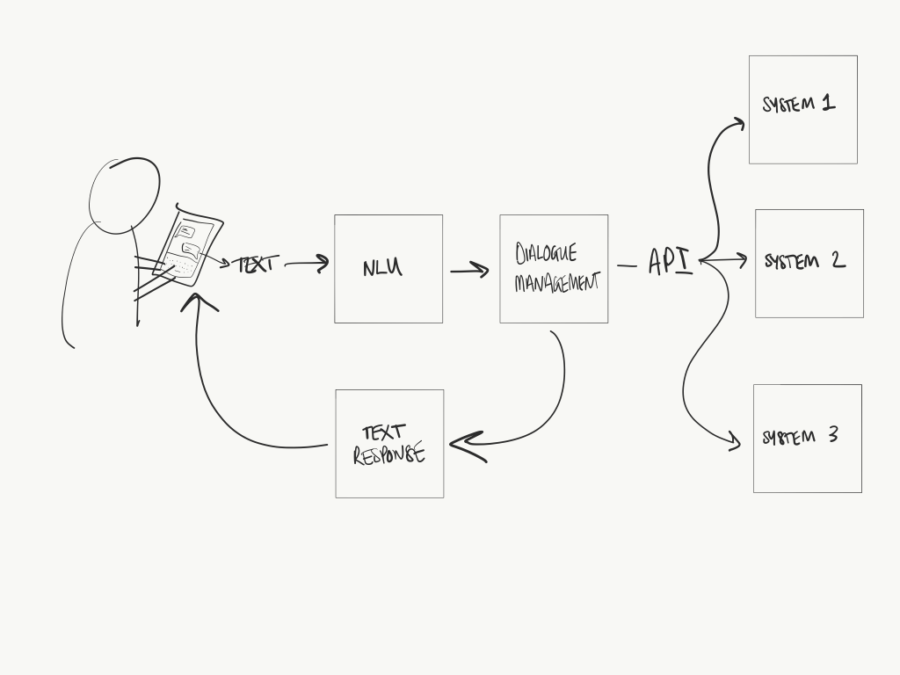
Where Natural Language Understanding fits within the AI chatbot technical pipeline.
With voicebots, most voice applications use ASR (automatic speech recognition) first. The ASR translates audible spoken words into text. Think of it like automatic transcriptions. That text is then sent to the NLU, as it is with a chatbot.
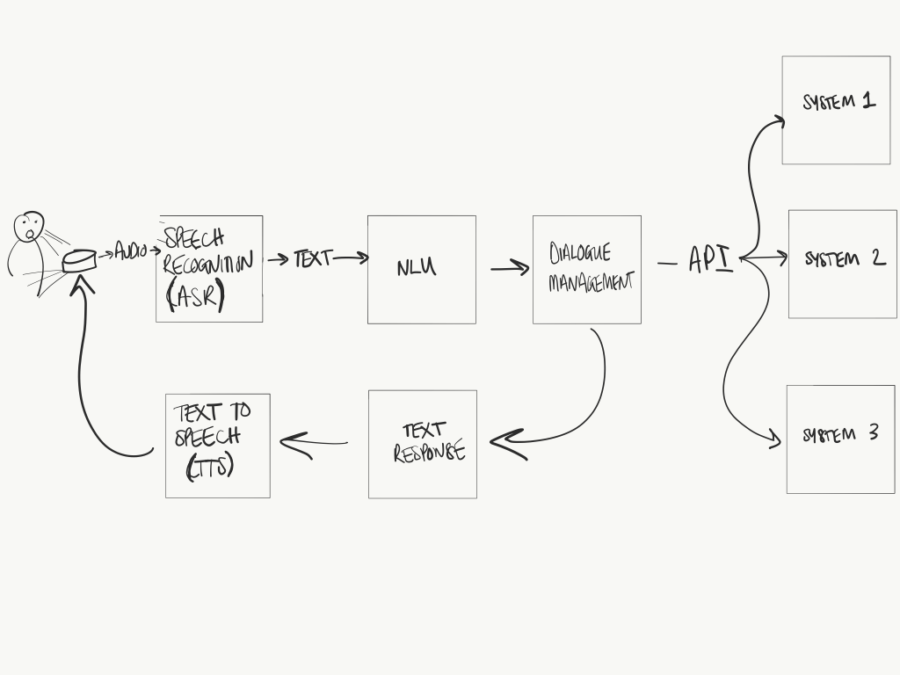
An example of where Natural Language Understanding sits within most, not all, voice AI tech pipelines.
I emphasised the word ‘most’ just then. That’s because not all voice user interfaces use ASR, followed by NLU. Some blend the two together.
For example, Speakeasy AI has patented ‘speech to intent’ technology that analyses audio alone and matches that directly to an intent. Speechly does something similar. In this instance, the NLU includes the ASR and it all works together.
Where can I find NLU providers?
There are a flurry of NLU providers on the market. Some small, some large. The main providers that you might be familiar with are:
Then there are open source NLU tools such as Rasa and a range of conversational AI platforms on the market, which have NLU built-in. Some have their own proprietary NLU, others use one (or all) of the cloud providers above behind the scenes.
The rise of Natural Language Understanding
It’s likely only a matter of time before you’re asked to design or build a chatbot or voice assistant. Now that you know the basics, you should have what it takes to be able to talk about NLU with a degree of understanding, and maybe even enough to start using NLU systems to create conversational assistants right away.
Anything we missed? Let us know!